Paper Reading: Control of a Quadrotor With Reinforcement Learning
Motivation
The advantage of reinforcement learning over optimization approaches and guided policy search methods is that it does not need a predefined controller structure which limits the performance of the agent and costs more human effort.
Although reinforcement learning has been used in robotics for many decades, it has largely been confinde to higher-level decisions rather than low actuator commands.
Contributions
- Map state to actuator command (
rotor thrusts) directly - Present a new learning algorithm which is built on
deterministic policy optimizationusing a natural gradient descent- value estimate from on-policy samples have
lower variance - write the policy gradient in a
simpler form stochastic policycan lead to poor andunpredictableperformance
- value estimate from on-policy samples have
- Demonstrate the trained policy both in simulation and with a real quadrotor
- Computation time of the policy is only \(7 \mu s\) per time step
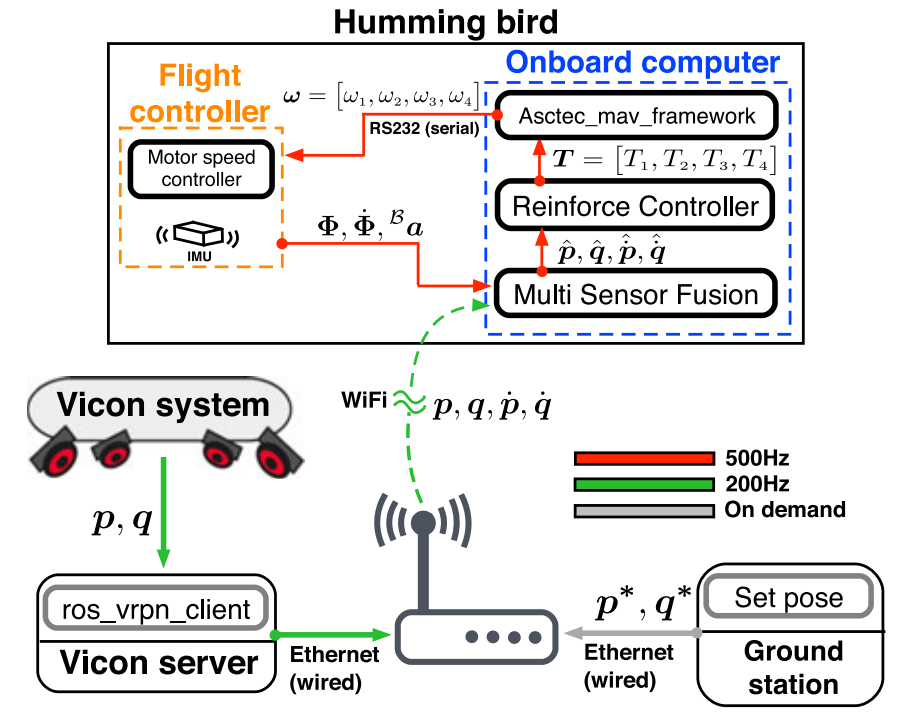
Method
Network Structure
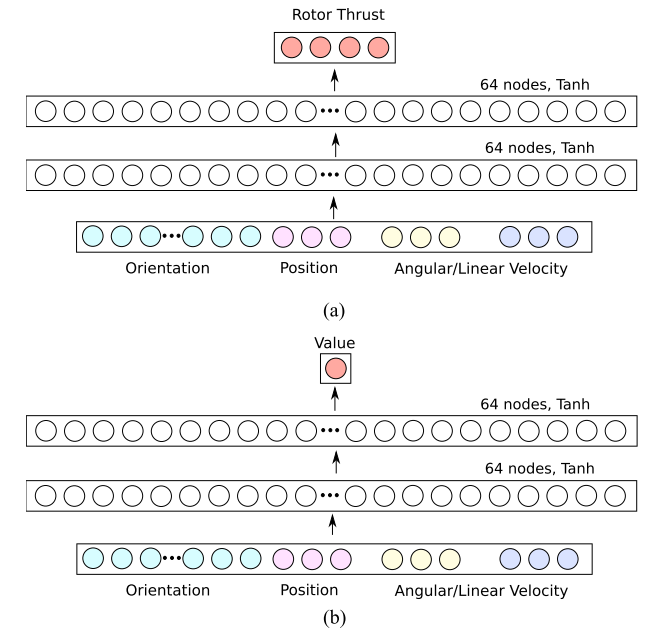
- Value network
- Input: State, 18-dimensional vector (rotation matrix, positon, linear velocity, angular velocity)
- 9D rotation matrix: represent the rotation, quaternion has a pitfall that two values represent the same rotation (\(q = -q\))
- 3D position-target position
- 3D linear velocity
- 3D angular velocity
- Output: Value function
- Input: State, 18-dimensional vector (rotation matrix, positon, linear velocity, angular velocity)
- Policy network
- Input: State, 18-dimensional vector (rotation matrix, positon, linear velocity, angular velocity)
- Output: Action, 4-dimensional vector (
rotor thrust)
UAV Model for Simulation
\[J^T T = M a + h,\]where,
- \(J\) is the stacked Jacobian matrices of the centers of the rotors.
- \(T\) is the thrust forces.
- \(M\) is the inertia matrix.
- \(a\) is the generalized acceleration.
- \(h\) is the coriolis and gravity effect.
The model ignores all drag forces acting on the body and use a simple floating body model with four thrust forces acting on the body.
Simulation Process
The output action motor thrusts have two parts, the sum of the two controllers used as a command:
- A simple Proportional and Derivative (PD) controller for attitude with low gains,
- The learning policy.
Why use a PD controller?
- The simulation sometimes become
unstablewhen the angular velocity becomes very high. - This is due to the fact that the algorithm initially
explores a large regionwhere we cannot simulate accurately. - The
gradientobserved when the quadrotor is upside-down is verylow and discontinuous. Then, the gradient-based algorithms take very long time to learn. - The PD controller alone is insufficient and generates very high costs.
- The quadrotor simply flies away since it is initialized with a high initial velocity.
The PD controller is used to stabilize the learning process but it does not aid the final controller since the final controller manifests much more sophisticated behaviors.
PD controller:
where,
- \(\tau_b\) is the virtual torque produced on the main body as a result of the thrust forces.
- \(k_p,k_d\) are the controller gains.
- \(R\) is the rotation matrix.
- \(q_{euler}\) is the orientation of the UAV in Euler vector.
- \(w\) is the angular velocity.
Algorithm
Value Function Training
\[v_i = \sum_{t=i}^{T-1}\gamma^{t-i}r_t^p + \gamma^{T-i}V(s_T \vert \eta),\]where \(\eta\) is the parameters of approximated value function, \(T\) is the length of the trajectory.
Policy Optimization

Reward Function
\[r_t = 4 \times 10^{-3} \Vert p_t \Vert + 2 \times 10^{-4} \Vert a_t \Vert + 3 \times 10^{-4} \Vert \omega_t \Vert + 5 \times 10^{-4} \Vert v_t \Vert,\]where \(p_t\), \(a_t\), \(\omega_t\) and \(v_t\) are the position, action (motor thrust), angular velocities and linear velocities, respectively.
Code
Some of the code:
Network forward function
Learned policy \(+\) PD controller \(\to\) Thrust \(\to\) Rotor speed.
The output of PD controller is \((\tau_\phi, \tau_\theta, \tau_\psi)\), then, the thrust of rotors can be obtained:
void forward(Eigen::Vector4d &quat,
Eigen::Vector3d &position,
Eigen::Vector3d &angVel,
Eigen::Vector3d &linVel,
Eigen::Vector3d &targetPosition,
Eigen::Vector4d &action) {
Eigen::Matrix3d R;
quatToRotMat(quat, R);
Eigen::Matrix<double, 18, 1> state;
state << R.col(0), R.col(1), R.col(2), (position-targetPosition+positionOffset) * positionScale_, angVel * angVelScale_, linVel * linVelScale_;
// std::cout<<"state" <<state.transpose()<<std::endl;
// std::cout<<"quat" <<quat.transpose()<<std::endl;
// action = w3 * (w2 * (w1*state +b1).array().tanh().matrix() + b2).array().tanh().matrix() + b3;
Eigen::Matrix<double, 64, 1> l1o = w1 * state + b1;
for (int i = 0; i < 64; i++)
l1o(i) = std::tanh(l1o(i));
Eigen::Matrix<double, 64, 1> l2o = w2 * l1o + b2;
for (int i = 0; i < 64; i++)
l2o(i) = std::tanh(l2o(i));
action = w3 * l2o + b3;
double angle = 2.0 * std::acos(quat(0));
double kp_rot = -0.2, kd_rot = -0.06;
Eigen::Vector3d B_torque;
if(angle > 1e-6)
B_torque = kp_rot * angle * (R.transpose() * quat.tail(3))
/ std::sin(angle) + kd_rot * (R.transpose() * angVel);
else
B_torque = kd_rot * (R.transpose() * angVel);
B_torque(2) = B_torque(2) * 0.15;
Eigen::Vector4d genForce;
genForce << B_torque, mass_ * 9.81;
// std::cout<<"genForce "<<genForce.transpose()<<std::endl;
Eigen::Vector4d thrust;
thrust = transsThrust2GenForceInv * genForce + 2.0 * action;
thrust = thrust.cwiseMax(1e-6);
Eigen::Vector4d rotorSpeed;
// rotorSpeed(0) = std::sqrt(thrust(0) / 0.00015677);
// rotorSpeed(1) = std::sqrt(thrust(1) / 0.000123321);
// rotorSpeed(2) = std::sqrt(thrust(2) / 0.00019696);
// rotorSpeed(3) = std::sqrt(thrust(3) / 0.00015677);
rotorSpeed = (thrust.array() / 8.5486e-6).sqrt();
action = rotorSpeed;
}
Step and Reward function
void step(const Action &action_t,
State &state_tp1,
TerminationType &termType,
Dtype &costOUT) {
//Get current state from q_, u_
orientation = q_.head(4); //Orientation of quadrotor
double angle = 2.0 * std::acos(q_(0)); //Angle of rotation
position = q_.tail(3); //Position of quadrotor
R_ = Math::MathFunc::quatToRotMat(orientation); //Calculate rotation matrix
v_I_ = u_.tail(3); //linear velocity
w_I_ = u_.head(3); //angular velocity
w_B_ = R_.transpose() * w_I_; //body rates // TODO: u_.head(3) = w_I_
//Control input from action
Action actionGenForce;
actionGenForce = transsThrust2GenForce * actionScale_ * action_t; //Force generated by action
B_torque = actionGenForce.segment(0, 3); //Moment input
B_force << 0.0, 0.0, actionGenForce(3); // Thrust vector in {B}
//Control input from PD stabilization
double kp_rot = -0.2, kd_rot = -0.06;
Torque fbTorque_b;
if (angle > 1e-6)
fbTorque_b = kp_rot * angle * (R_.transpose() * orientation.tail(3))
/ std::sin(angle) + kd_rot * (R_.transpose() * u_.head(3));
else
fbTorque_b = kd_rot * (R_.transpose() * u_.head(3));
fbTorque_b(2) = fbTorque_b(2) * 0.15; //Lower yaw gains
B_torque += fbTorque_b; //Sum of torque inputs
B_force(2) += mass_ * 9.81; //Sum of thrust inputs
// clip inputs
Action genForce;
genForce << B_torque, B_force(2);
Action thrust = transsThrust2GenForceInv * genForce; // TODO: This is not exactly thrust: change name
thrust = thrust.array().cwiseMax(1e-8); // clip for min value
genForce = transsThrust2GenForce * thrust;
B_torque = genForce.segment(0, 3);
B_force(2) = genForce(3);
du_.tail(3) = (R_ * B_force) / mass_ + gravity_; // acceleration
du_.head(3) = R_ * (inertiaInv_ * (B_torque - w_B_.cross(inertia_ * w_B_))); //acceleration by inputs
//Integrate states
u_ += du_ * this->controlUpdate_dt_; //velocity after timestep
w_I_ = u_.head(3);
w_IXdt_ = w_I_ * this->controlUpdate_dt_;
orientation = Math::MathFunc::boxplusI_Frame(orientation, w_IXdt_);
Math::MathFunc::normalizeQuat(orientation);
q_.head(4) = orientation;
q_.tail(3) = q_.tail(3) + u_.tail(3) * this->controlUpdate_dt_;
w_B_ = R_.transpose() * u_.head(3);
// visualizer_.drawWorld(visualizeFrame, position, orientation);
if (std::isnan(orientation.norm())) {
std::cout << "u_ " << u_.transpose() << std::endl;
std::cout << "du_ " << du_.transpose() << std::endl;
std::cout << "B_torque " << B_torque.transpose() << std::endl;
std::cout << "orientation " << orientation.transpose() << std::endl;
std::cout << "state_tp1 " << q_.transpose() << std::endl;
std::cout << "action_t " << action_t.transpose() << std::endl;
}
u_(0) = clip(u_(0), -20.0, 20.0);
u_(1) = clip(u_(1), -20.0, 20.0);
u_(2) = clip(u_(2), -20.0, 20.0);
u_(3) = clip(u_(3), -5.0, 5.0);
u_(4) = clip(u_(4), -5.0, 5.0);
u_(5) = clip(u_(5), -5.0, 5.0);
getState(state_tp1);
// costOUT = 0.004 * q_.tail(3).norm() +
// 0.0002 * action_t.norm() +
// 0.0003 * u_.head(3).norm() +
// 0.0005 * u_.tail(3).norm();
costOUT = 0.004 * std::sqrt(q_.tail(3).norm()) +
0.00005 * action_t.norm() +
0.00005 * u_.head(3).norm() +
0.00005 * u_.tail(3).norm();
// std::cout << "distance cost " << 0.004 * q_.tail(3).squaredNorm() << std::endl;
// std::cout << "actuation cost " << 0.0002 * action_t.squaredNorm() << std::endl;
// std::cout << "angular velocity cost " << 0.0003 * u_.head(3).squaredNorm() << std::endl;
// std::cout << "orientation cost " << 0.0005 * acos(q_(0)) * acos(q_(0)) << std::endl;
// if (this->isViolatingBoxConstraint(state_tp1))
// termType = TerminationType::timeout;
// visualization
if (this->visualization_ON_) {
updateVisualizationFrames();
visualizer_.drawWorld(visualizeFrame, position, orientation);
double waitTime = std::max(0.0, this->controlUpdate_dt_ / realTimeRatio - watch.measure("sim", true));
watch.start("sim");
usleep(waitTime * 1e6);
}
}
void stepSim(const Action &action_t) {
Action thrust = action_t.array().square() * 8.5486e-6;
thrust = thrust.array().cwiseMax(1e-8);
Eigen::Matrix<Dtype, 4, 1> genforce;
genforce = transsThrust2GenForce * thrust;
B_torque = genforce.segment(0,3);
B_force << 0.0, 0.0, genforce(3);
orientation = q_.head(4);
double angle = 2.0 * std::acos(q_(0));
position = q_.tail(3);
R_ = Math::MathFunc::quatToRotMat(orientation);
// std::cout<<"genForce "<<genForce.transpose()<<std::endl;
// std::cout<<"angle "<<angle<<std::endl;
// std::cout<<"orientation.tail(3) / std::sin(angle) "<< orientation.tail(3) / std::sin(angle) <<std::endl;
// std::cout<<"proportioanl part "<< kp_rot * angle * ( R_.transpose() * orientation.tail(3) ) / std::sin(angle) <<std::endl;
// std::cout<<"diff part "<< kd_rot * ( R_.transpose() * u_.head(3) ) <<std::endl;
du_.tail(3) = (R_ * B_force) / mass_ + gravity_;
w_B_ = R_.transpose() * u_.head(3);
/// compute in body coordinate and transform it to world coordinate
// B_torque += comLocation_.cross(mass_ * R_.transpose() * gravity_);
du_.head(3) = R_ * (inertiaInv_ * (B_torque - w_B_.cross(inertia_ * w_B_)));
u_ += du_ * this->controlUpdate_dt_;
w_I_ = u_.head(3);
w_IXdt_ = w_I_ * this->controlUpdate_dt_;
orientation = Math::MathFunc::boxplusI_Frame(orientation, w_IXdt_);
Math::MathFunc::normalizeQuat(orientation);
q_.head(4) = orientation;
q_.tail(3) = q_.tail(3) + u_.tail(3) * this->controlUpdate_dt_;
w_B_ = R_.transpose() * u_.head(3);
if ( std::isnan(orientation.norm()) ) {
std::cout << "u_ " << u_.transpose() << std::endl;
std::cout << "du_ " << du_.transpose() << std::endl;
std::cout << "B_torque " << B_torque.transpose() << std::endl;
std::cout << "orientation " << orientation.transpose() << std::endl;
std::cout << "state_tp1 " << q_.transpose() << std::endl;
std::cout << "action_t " << action_t.transpose() << std::endl;
}
// visualization
if (this->visualization_ON_) {
updateVisualizationFrames();
visualizer_.drawWorld(visualizeFrame, position, orientation);
double waitTime = std::max(0.0, this->controlUpdate_dt_ / realTimeRatio - watch.measure("sim", true));
watch.start("sim");
usleep(waitTime * 1e6);
}
}