Research




My research topics include deep reinforcement learning (RL), Robust RL, learning-based control, real-time trajectory planning, and moving target detection and tracking, etc.
Feel free to contact me if you are interested in some of these projects. (Email: sychenhit@foxmail.com)
Real-time Quadrotor Trajectory Planning
Learning Real-Time Dynamic Responsive Gap-Traversing Policy for Quadrotors with Safety-Aware Exploration
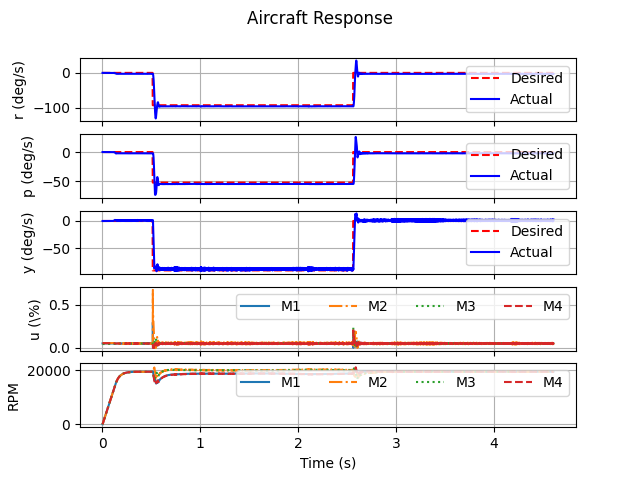
In this paper, we propose a dynamic responsive policy for a quadrotor to traverse through narrow gaps based on deep reinforcement learning (RL). The policy provides agile and dynamically adjusted gap-traversing actions for the quadrotor in real-time by directly mapping the observed states of the quadrotor and gaps to motor thrusts. In contrast to existing optimization-based methods, our RL-based policy couples trajectory planning and control modules, which are strictly independent and computationally complex in previous works. Moreover, a safety-aware exploration is presented to reduce the collision risk and improve the safety of the policy, which also facilitates the transfer of the policy to real-world environments. Specifically, we formulate a safety reward on the state spaces of both position and orientation to inspire the quadrotor to traverse through the narrow gap at an appropriate attitude closer to the center of the gap. With the learned gap-traversing policy, we implement extensive simulations and real-world experiments to evaluate its performance and compare it with the related approaches. Our implementation includes several gap-traversing tasks with random positions and orientations, even if never trained specially before. All the performances indicate that our RL-based gap-traversing policy is transferable and more efficient in terms of real-time dynamic response, agility, time-consuming, and generalization.


The RL framework and quadrotor hardware platform for gap-traversing tasks.
![]()
![]()


Quadrotor traversing through narrow gap in diverse scenarios.

Quadrotor recovering from collision.
Robust and Agile Quadrotor Low-Level Control
Agile Quadrotor Low-Level Control with Deep Reinforcement Learning

The RL-based control framework and software structure of the quadrotor (RLG-AF1).
RLG-AF1 tracking trajectories with only onboard sensing and computation.


Robustness tests of the quadrotor with random external thrusts and payload change.

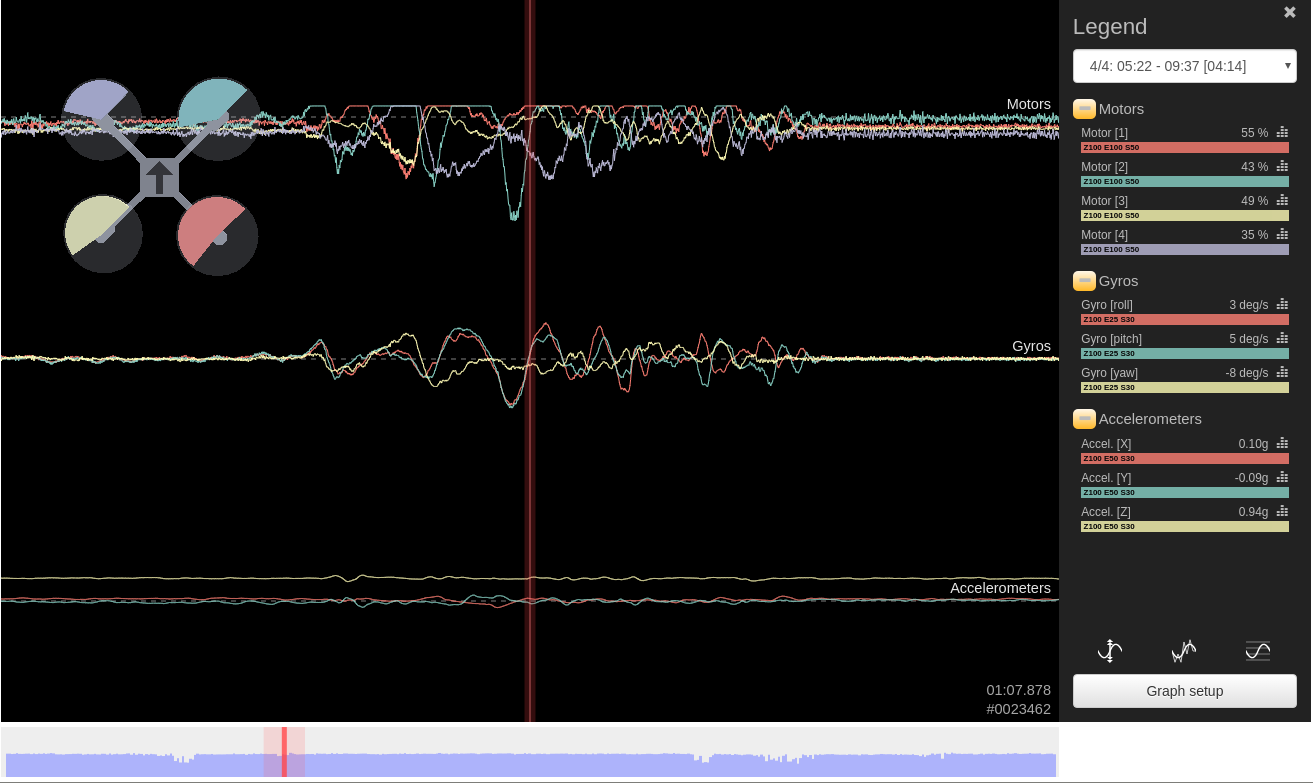
RLG-AF1 hovering with only onboard sensing and computation.
Trajectory Generation and Tracking
![]()
![]()
Learning Agile Quadrotor Flight in Restricted Environments with Safety Guarantees
With the increasing requirement for agile and efficient controllers in safety-critical scenarios, controllers that exhibit both agility and safety are attracting attention, especially in the aerial robotics domain. This paper focuses on the safety issue of Reinforcement Learning (RL)-based control for agile quadrotor flight in restricted environments. To this end, we propose a unified Adaptive Safety Predictive Corrector (ASPC) to certify each output action of the RL-based controller in real-time, ensuring its safety while maintaining agility. Specifically, we develop the ASPC as a finite-horizon optimal control problem, formulated by a variant of Model Predictive Control (MPC). Given the safety constraints determined by the restricted environment, the objective of minimizing loss of agility can be optimized by reducing the difference between the actions of RL and ASPC. As the safety constraints are decoupled from the RL-based control policy, the ASPC is plug-and-play and can be incorporated into any potentially unsafe controllers. Furthermore, an online adaptive regulator is presented to adjust the safety bounds of the state constraints with respect to the environment changes, extending the proposed ASPC to different restricted environments. Finally, simulations and real-world experiments are demonstrated in various restricted environments to validate the effectiveness of the proposed ASPC.
- Safety Certification Mechanism
- Decoupled Safety Constraints
- Optimization-based Safety prediction and Correction
- Real-time Control for Quadrotors with Safety Guarantees

Adaptive PID Parameter Adjustment and End-to-end Attitude Control for Quadrotors with Deep Reinforcement Learning
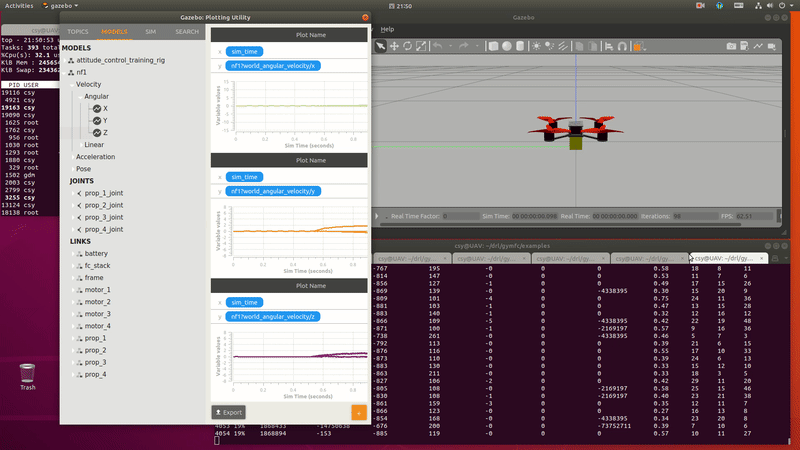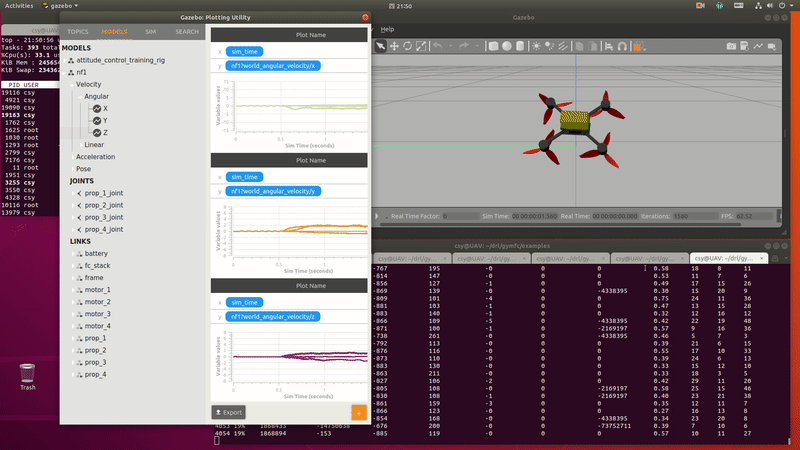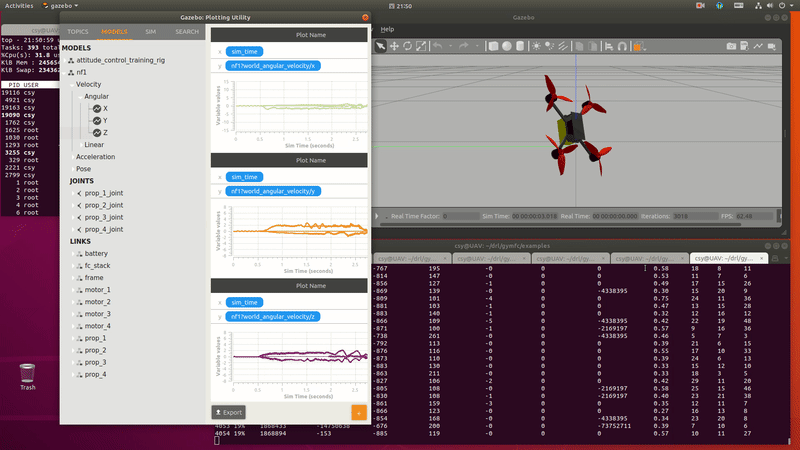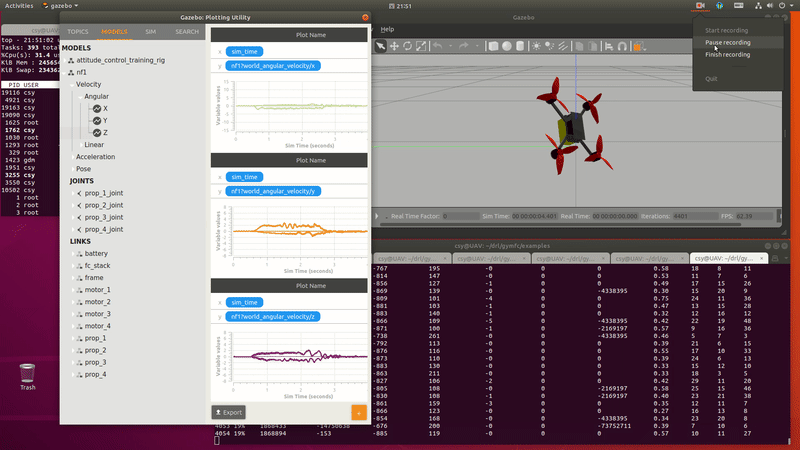
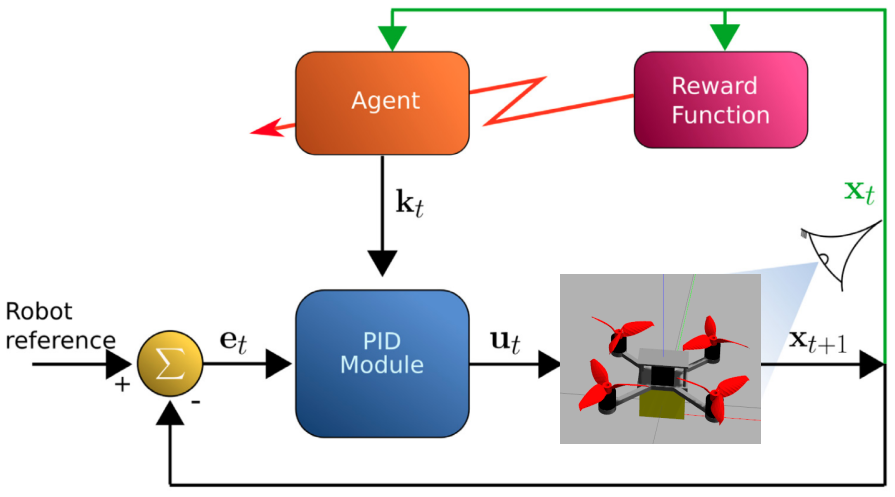
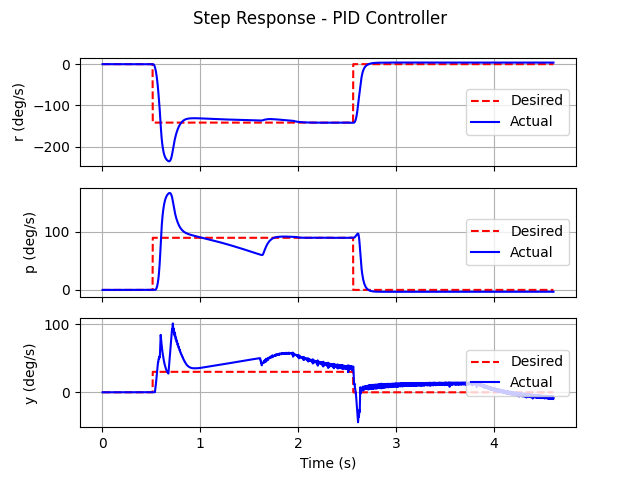
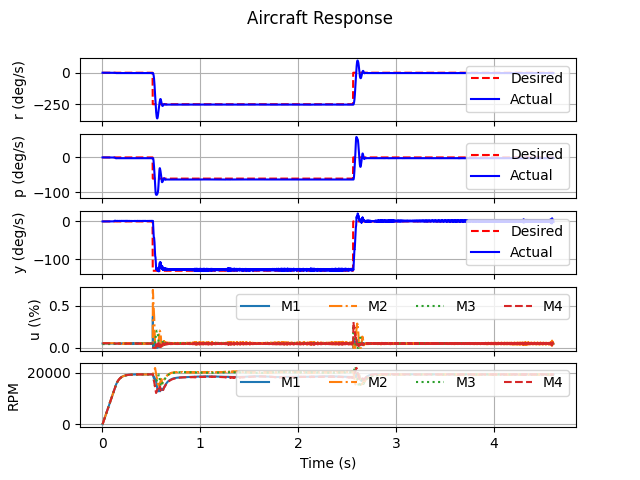
PID control $\to$ RL for PID parameter adjustment $\to$ RL control
Quadrotor Hardware Platform
Quadrotor Dynamics Modeling and Identification



Quadrotor RLG-AF1








PCB (Printed Circuit Board) Design for Quadrotor Autopilot


Moving Target Detection and Tracking
S. Chen, S. Guo, and Y. Li, “Real-Time tracking a ground moving target in complex indoor and outdoor environments with UAV,” in 2016 IEEE International Conference on Information and Automation (ICIA), 2016, pp. 362–367.
S. Chen, Y. Li, and H. Chen, “A monocular vision localization algorithm based on maximum likelihood estimation,” IEEE International Conference on Real-Time Computing and Robotics (RCAR), 2017, pp. 561–566.
In this project, we present a complete strategy of tracking a ground moving target in complex indoor and outdoor environments with an unmanned aerial vehicle (UAV) based on computer vision. The main goal of this system is to track a ground moving target stably and get the target back when it is lost. An embedded camera on the UAV platform is used to provide real-time video stream to the onboard computer where the target recognition and tracking algorithms are running. A vision-based position estimator is applied to localize the position of UAV. According to the position of the ground target obtained from the 2-dimensional images, corresponding control strategy of the UAV is implemented. Simulation of UAV and ground moving target with the target-tracking system is performed to verify the feasibility of the mission. After the simulation verification, a series of real-time experiments are implemented to demonstrate the performance of the target-tracking strategy.
![]()
![]()
![]()
![]()
The software framework and Sim-to-Real transfer of the quadrotor-target tracking system.
Motion Planning for Autonomous Driving
Motion Planner with Fixed-Horizon Constrained Reinforcement Learning for Complex Autonomous Driving Scenarios
In autonomous driving, behavioral decision-making and trajectory planning remain huge challenges due to the large amount of uncertainty in environments and complex interaction relationships between the ego vehicle and other traffic participants. In this paper, we propose a novel fixed-horizon constrained reinforcement learning (RL) framework to solve decision-making and planning problems. Firstly, to introduce lane-level global navigation information into the lane state representation and avoid constant lane changes, we propose the constrained A-star algorithm, which can get the optimal path without constant lane changes. The optimality of the algorithm is also theoretically guaranteed. Then, to balance safety, comfort, and goal completion (reaching targets), we construct the planning problem as a constrained RL problem, in which the reward function is designed for goal completion, and two fixed-horizon constraints are developed for safety and comfort, respectively. Subsequently, a motion planning policy network (planner) with vectorized input is constructed. Finally, a dual ascent optimization method is proposed to train the planner network. With the advantage of being able to fully explore in the environment, the agent can learn an efficient decision-making and planning policy. In addition, benefiting from modeling the safety and comfort of the ego vehicle as constraints, the learned policy can guarantee the safety of the ego vehicle and achieve a good balance between goal completion and comfort. Experiments demonstrate that the proposed algorithm can achieve superior performance than existing rule-based, imitation learning-based, and typical RL-based methods.

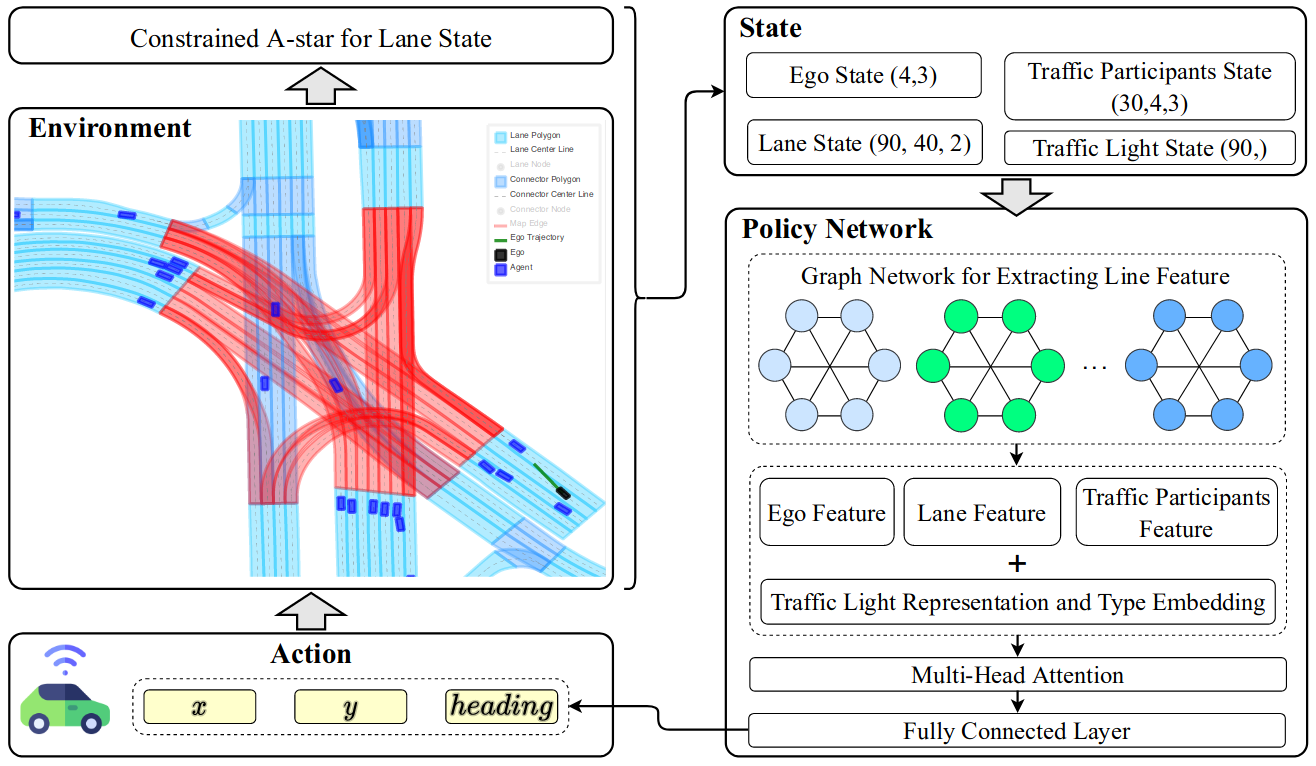
The RL framework for autonomous driving.
Reinforcement Learning (RL) Theory and Framework
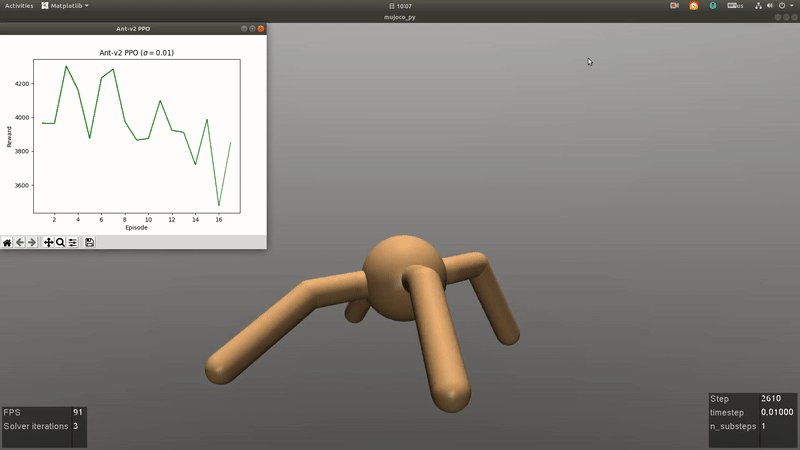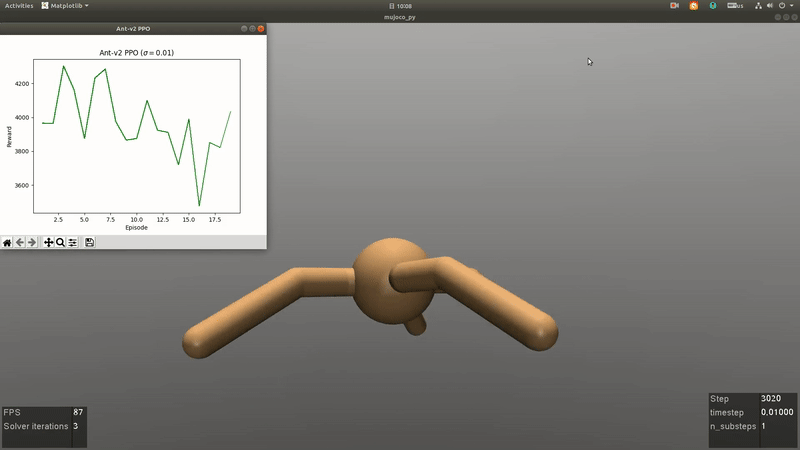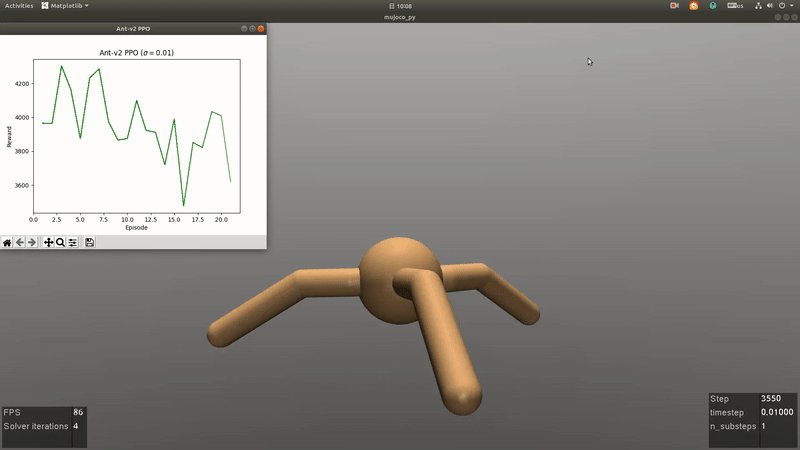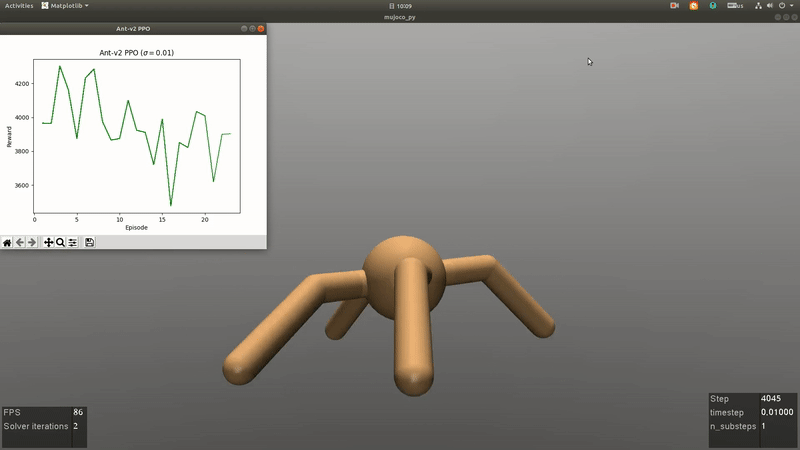
RL for Games
An Overview of Robust Reinforcement Learning
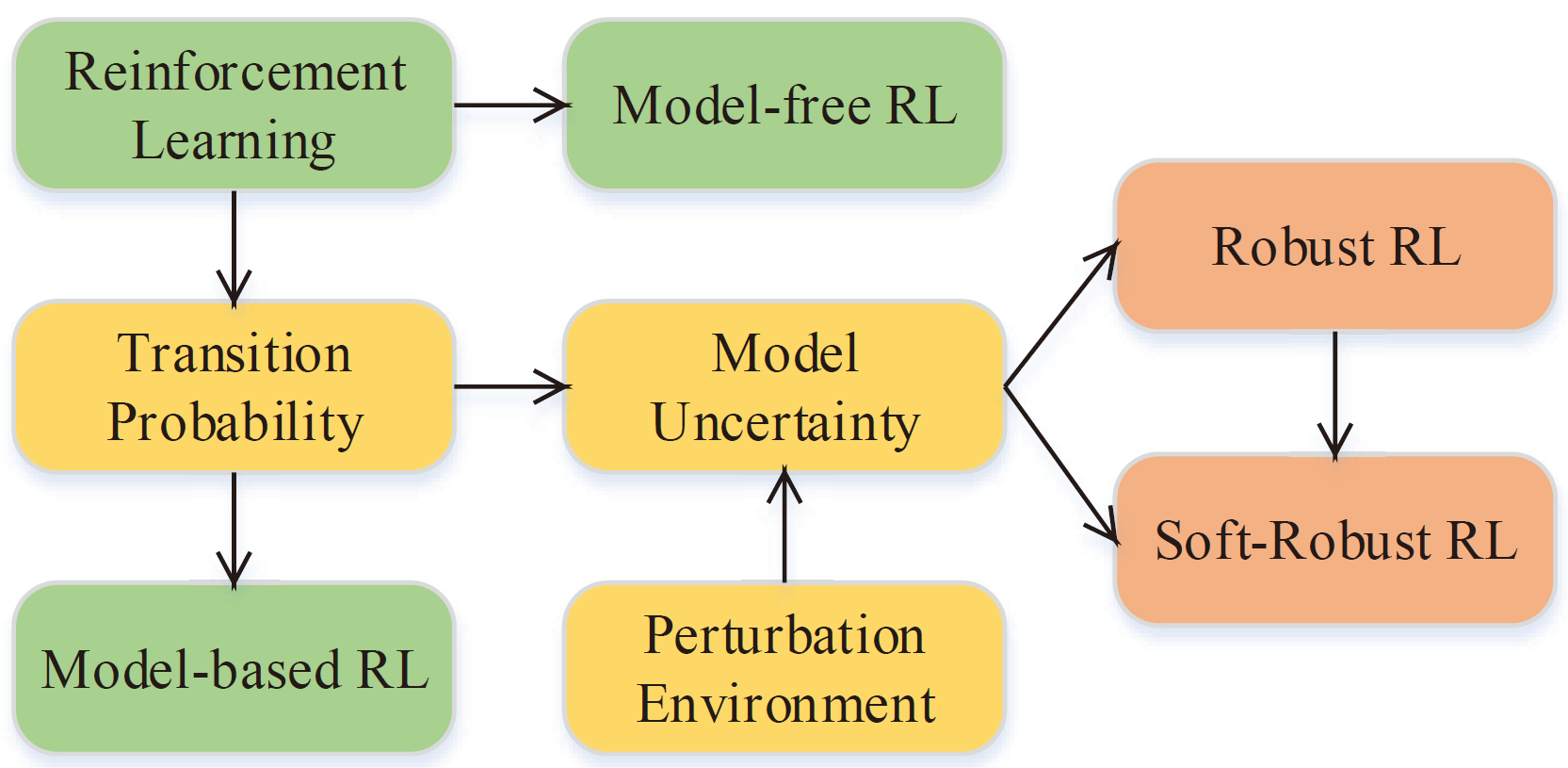
Reinforcement learning (RL) is one of the popular methods for intelligent control and decision making in the field of robotics recently. The goal of RL is to learn an optimal policy of the agent by interacting with the environment via trail and error. There are two main algorithms for RL problems, including model-free and model-based methods. Model-free RL is driven by historical trajectories and empirical data of the agent to optimize the policy, which needs to take actions in the environment to collect the trajectory data and may cause the damage of the robot during training in the real environment. The main different between model-based and model-free RL is that a model of the transition probability in the interaction environment is employed. Thus the agent can search the optimal policy through internal simulation. However, the model of the transition probability is usually estimated from historical data in a single environment with statistical errors. Therefore, an issue is faced by the agent is that the optimal policy is sensitive to perturbations in the model of the environment which can lead to serious degradation in performance. Robust RL aims to learn a robust optimal policy that accounts for model uncertainty of the transition probability to systematically mitigate the sensitivity of the optimal policy in perturbed environments. In this overview, we begin with an introduction to the algorithms in RL, then focus on the model uncertainty of the transition probability in robust RL. In parallel, we highlight the current research and challenges of robust RL for robot control. To conclude, we describe some research areas in robust RL and look ahead to the future work about robot control in complex environments.
![]()
![]()
![]()
![]()