Paper Reading: Reinforcement Learning for UAV Attitude Control
Motivation
More sophisticated control is required to operate in unpredictable and harsh environments. So, intelligent flight control systems is an active area of research addressing the limitations of PID control most recently through the use of reinforcement learning.
However, previous works have focused primarily on using RL at the mission-level controller.
Flight control is still considered as an open research topic, because it inheretly implies the ability to perform highly time-sensitive sensory data acquisition, processing and computation of forces to apply to the aircraft actuators. Also, it is desirable that the flight controller is able to tolerate faults, adapt to changes in the payload and environment, and to optimize flight trajectory.
In stable environments, a PID controller exhibits close-to-ideal performance. When exposed to unknown dynamics (e.g. wind, variable payloads, voltage sag, etc), the PID controller can be far from optimal.
Contributions
- Autopilot system
- Inner loop: stability and control
- PID (Proportional Integral Derivative): far from optimal when exposed to unknown dynamics (wind, variable payloads, voltage sag, etc)
Intelligent flight control system- RL (DDPG, TRPO, PPO)
- Outer loop: mission-level objectives (way-point navigation, target-tracking)
- Inner loop: stability and control
GymFC: developed an open-source high-fidelity simulation environment- An evaluation for DDPG, TRPO, PPO, learning policies for aircraft
attitude control
Method
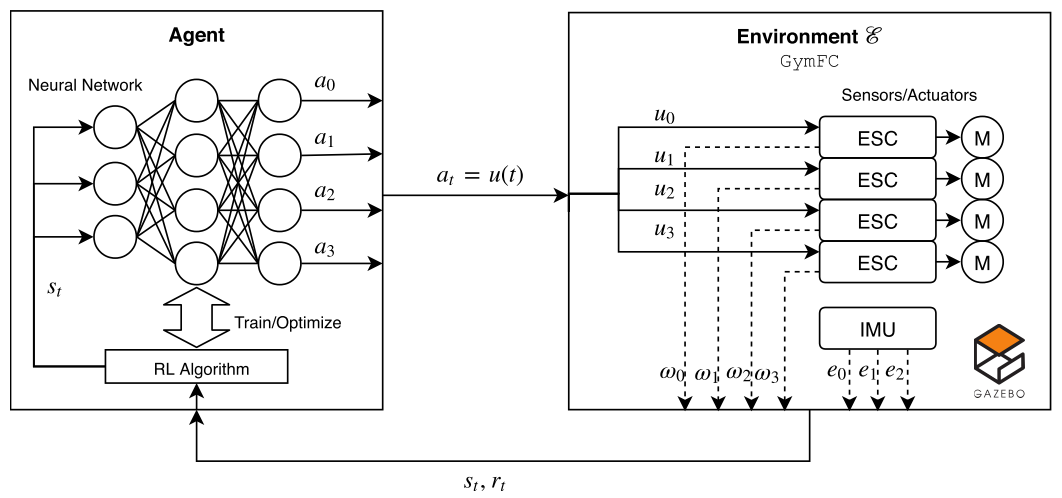
State
- Observation: \(x_t = (w_0,w_1,w_2,w_3,e_0,e_1,e_2) \in \mathbb{R}^{4+3}\).
- Action: \(a_t = (u_0,u_1,u_2,u_3) \in \mathbb{R}^4\).
Where \(w_0,w_1,w_2,w_3\) denote the speed of each motor, \(e = \Omega^* - \Omega\) is the angular velocity error of each axis.
Consider the state to be a sequence of the past observations and actions:
\[s_t = x_i, a_i, \cdots, a_{t-1}, x_t.\]Action
\[a_t = (u_0,u_1,u_2,u_3),\]where \(a_t\) denotes the four control signals sent to each motor.
Reward
\[r_t = - clip(sum(\vert \Omega_t^* - \Omega_t \vert)/3\Omega_{max}),\]where the function “sum” sums the absolute value of the error of each axis, and the “clip” function clips the result between \([0,1]\).
Simulation Environment
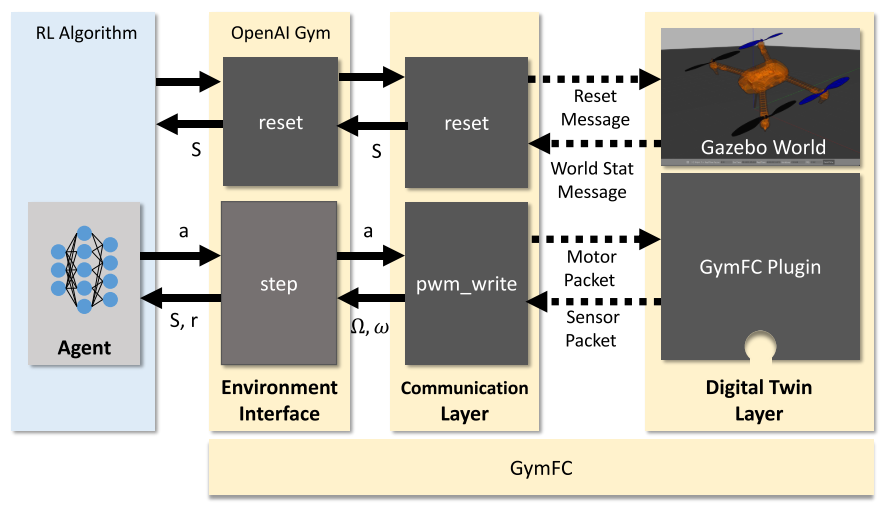
Digital Twin Layer
- The simulated world:
fixing the center of mass of the quadrotor to a ball jointin the world. - Its interfaces to the above communication layer.
- Simulation reset: Gazebo’s API.
- Motor update: Use
GymFC Pluginto work around the limitations of Gazebo’s Google Protobuf API and increased step throughput by over 200 times.
Communication Layer
- Use asynchronous communication protocols.
pwm_write
Environment Interface Layer
- OpenAI Gym environment API
- Observation space
- Action space
- State size: \(m \times (4+3)\), where \(m\) is the memory size of the number of past observations, each observation value is in \([-\infty, +\infty]\).
- Action size: \(4\), each value is normalized between \([-1,1]\).
reset: return the initial environment state. The function is called at thestart of an episodeand also when thedesired target angular velocity or setpointis computed. The setpoint is randomly sampled from a uniform distribution between \([\Omega_{min}, \Omega_{max}]\).step: execute a step with actions and return a new state vector, a reward.