Paper Reading: Flying Through a Narrow Gap Using Neural Network - an End-to-end Planning and Control Approach
Contributions
Proposed an end-to-end policy network which takes the flight scenario as input and directly outputs thrust-attitude control commands for the quadrotor.
- Present an imitate-reinforce training framework
- Flying through a narrow gap using an end-to-end policy network
- Propose a robust imitation of an optimal trajectory generator using multilayer perceptions
- Show how reinforcement learning can improve the performance of imitation learning
Code and Results
Code: https://github.com/hku-mars/crossgap_il_rl
Results: https://www.youtube.com/watch?v=jU1qRcLdjx0
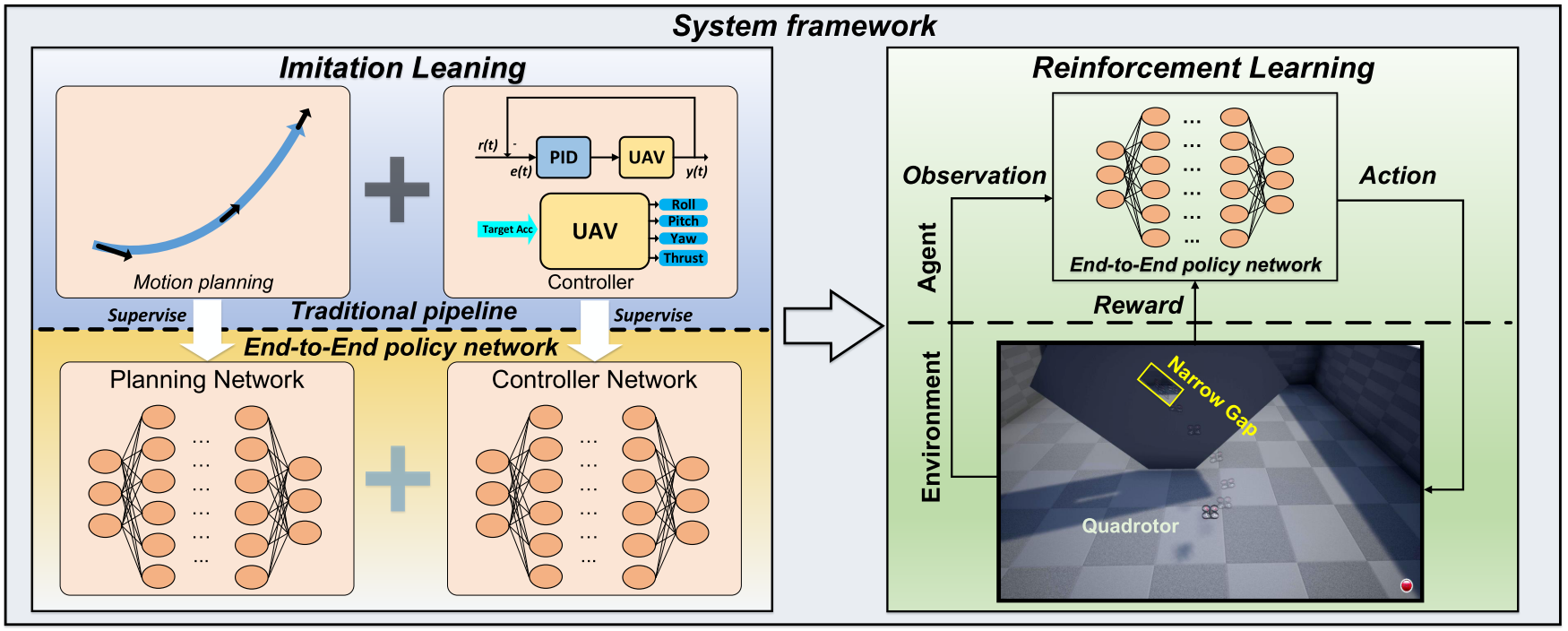
End-to-end method VS Traditional Pipeline
Traditional pipeline
Perception-Planning-Control:
- Estimate the robot state
- Build a map of its surrounding environment by SLAM
- A smooth, optimal trajectory is usually planned based on the map
- Track the generated trajectory by a low-level geometric controller
Usually applied in low-speed, static environments.
For aggressive robot maneuvers in cluttered, dynamic environments, such as drones racing in bush or indoor scenario, this pipeline becomes quite challenging because SLAM and trajectory optimization is memory and computationally expensive and degrade in performance for aggressive, dynamic maneuvers in non-static environments.
End-to-end method
Train a control policy that directly maps sensory inputs to control outputs.
Shorter pipeline: less computation time
Challenges:
- Training data collected in trail tests
- The trained policy network has no mathematical proof on its stability nor robustness
Method
Goal: Drone flying through a narrow gap
- maximum speed up to \(3m/s\)
- orientation angle up to \(60^{\circ}\)
Planning Network
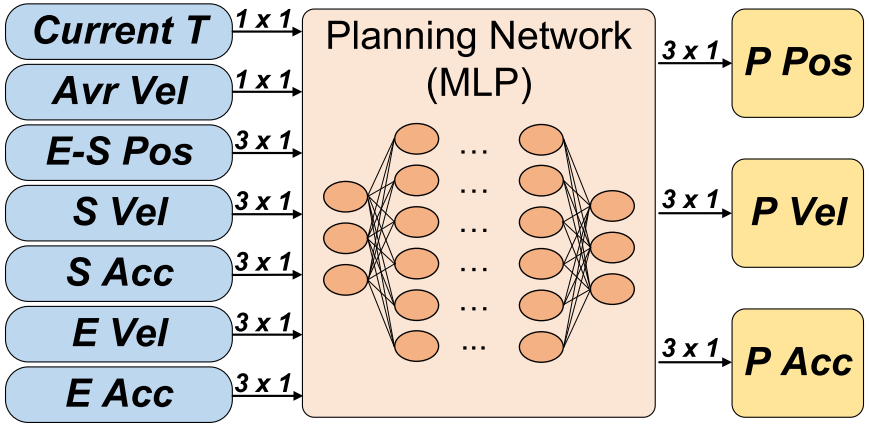
Inputs: \(17 \times 1\) vector
Outputs: \(9 \times 1\) vector, including \(\Delta p_p, v_p, a_p\)
Loss Function:
where \(\Delta p_l, v_l, a_l\) are the relative position, velocity, acceleration of labeling data generated from a conventional motion planner.
Controller Network
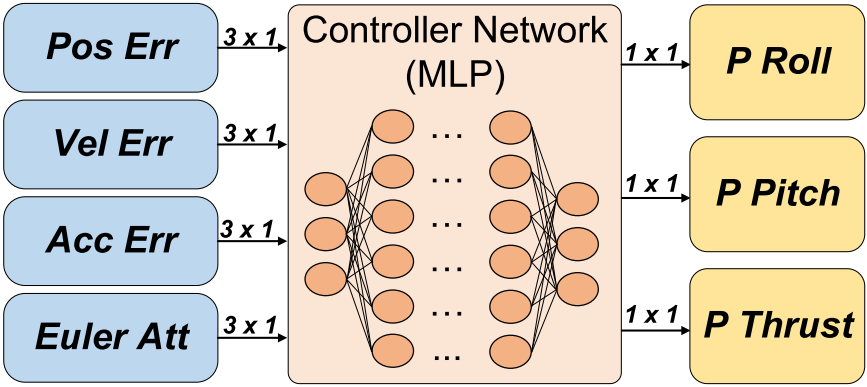
Inputs: \(12 \times 1\) vector, \(e_p, e_v, e_a\), Euler attitude
Outputs: \(3 \times 1\) vector, \(\phi_p \in [-30,30], \theta_p \in [-30,30], \mu_p \in [0,1]\)
Loss Function:
End-to-end Planning and Control
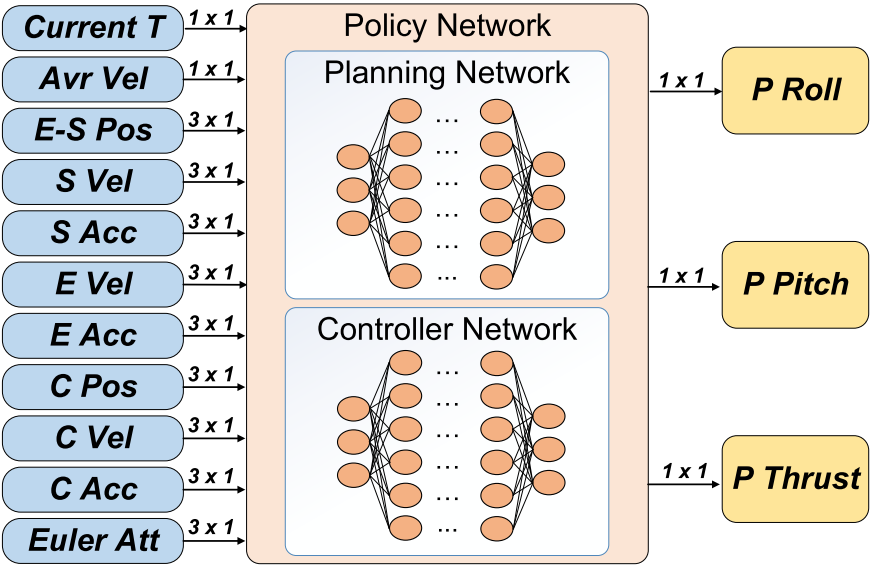
Inputs:
- \(17 \times 1\) vector for planning network
- \(12 \times 1\) vector of current state
The input of the controller network is:
- \(e_p = \Delta p_p - \Delta p_c\).
- \(e_v = v_p - v_c\).
- \(e_a = a_p - a_c\).
Outputs: \(3 \times 1\) vector, \(\phi_p, \theta_p, \mu_p\)
RL to improve the performance of Imitation Learning
Reward Function:
(1) Negative reward item:
\[R_{neg}(t) = - \left( w_w \Vert w(t) \Vert + w_\alpha \bigg\Vert \frac{dw(t)}{dt} \bigg\Vert + w_j \bigg\Vert \frac{da(t)}{dt} \bigg\Vert \right) \Delta t + C,\]where \(w(t)\) and \(a(t)\) are the angular velocity and linear acceleration, \(C\) is the collision penalty, if the drone collides with anything (i.e. wall, ground and etc), \(C\) will be set to \(10^9\).
(2) Positive reward item: if the drone reaches the center of gap, a positive reward will be given
\[R_{pos}(t) = (w_r \max (0, d_a - \Vert p_c - p(t) \Vert))\Delta t + S,\]where \(d_a\) is the activate distance of positive reward, \(S\) is a one-time reward which occurs at the first time the UAV obtains a positive reward.