Paper Reading: DPG With Integral Compensator for Robust Quadrotor Control
Contributions
- A reinforcement learning algorithm which can eliminate the steady-state error, the
DPG with integral compensator (DPG-IC)is developed to control quadrotor. - After obtaining a robust offline control policy based on a simplified quadrotor model, an online learning procedure is developed to continue optimizing the policy w.r.t. real flight dynamics.
- The quadrotor is controlled by a learned neural network which
directly maps the system states to control commandsin an end-to-end style.
Method
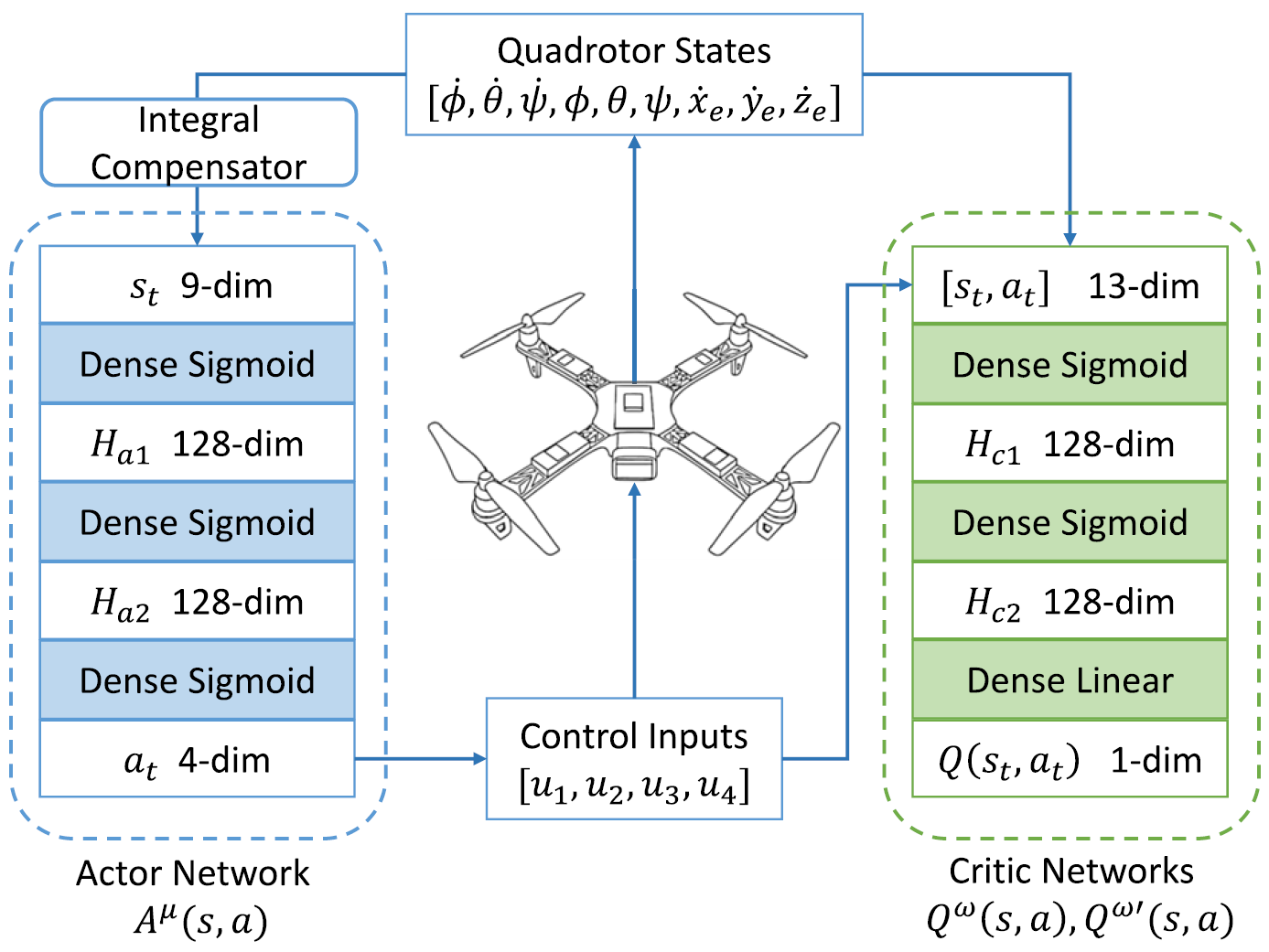
States
\[S = (\varphi, \theta, \psi, \dot{\varphi}, \dot{\theta}, \dot{\psi}, \dot{x_e}, \dot{y_e}, \dot{z_e}),\]where \(\dot{x_e} = \dot{x} - \dot{x_d}, \dot{y_e} = \dot{y} - \dot{y_d}, \dot{z_e} = \dot{z} - \dot{z_d}\) are the errors between current velocity and the desired velocity, and only design the velocity tracking controller.
Problem: DPG algorithms with neural networks suffer from an obvious steady-state error in tracking control tasks. Then, the learned policy cannot finally eliminate the tracking error.
Reason: One main reason is the inaccurate estimation of the action-value function. And it is much more difficult to make it more accurate from the critic network side.
Solve: Therefore, we make improvement on the actor network side. It is common to use integrator in controller design to deal with the steady-state error. We embed an integral compensator to the actor network structure.
Main idea: construct a set of compensated error states to replace the direct error states. The compensated error states are the combinations of direct errors and the integral of errors,
where \(s_e\) is the direct error state, \(s_c\) is the compensated error, and \(\beta\) is the integral gain.
Through the integral compensator, the direct error states \(\dot{x_e}, \dot{y_e}, \dot{z_e}\) are replaced with the compensated error states \(\dot{x_c}, \dot{y_c}, \dot{z_c}\). Then, the new 9-dimensional state vector change to:
\[S = (\varphi, \theta, \psi, \dot{\varphi}, \dot{\theta}, \dot{\psi}, \dot{x_c}, \dot{y_c}, \dot{z_c}).\]And this state vector is the actual input to the actor network.
Actions
\[A = (u_1,u_2,u_3,u_4).\]The spinning speeds are controlled by Pulse-Width-Modulation (PWM) signals through Electronic Speed Controllers (ESCs). The generated thrust is approximately proportional to the input PWM signal, that is
\[T_i = K u_i, \quad i = 1,2,3,4.\]Where \(T_i\) is the thrust, \(K\) is the thrust gain, \(u_i\) is the normalized control input PWM signal, the range of the input signal is \([0,1]\). The relationship between the thrusts and the accelerated velocity of quadrotor is shown in quadrotor dynamic model.
Reward
The control objective is to minimize the tracking errors in the shortest time. Thus, the reward function is the sum of tracking errors of each step:
\[r_t = - (\dot{x_e}^2 + \dot{y_e}^2 + \dot{z_e}^2 + \psi^2) + c,\]where \(c\) is a positive constant that guarantees the reward is positive. The desire heading angle \(\psi\) is simply set as \(0\).
Algorithm of DPG-IC

Two-Phase Learning Protocol
Offline learning phase
The offline control policy is learned from a highly simplified quadrotor model, which ignores all aerodynamic resistances, gyroscope effects and external disturbances.
In each episode, the quadrotor is initialized with a random state (random \(\varphi, \theta, \psi, \dot{\varphi}, \dot{\theta}, \dot{\psi}, \dot{x}, \dot{y}, \dot{z}, \dot{x_d}, \dot{y_d}, \dot{z_d}\)), and set a safe range for each state. By setting the safe range to limit the range of states, the exploration is more efficient and the values of the states can be easily normalized, also the safe range can help learning a safer policy.
The performance of the offline policy may not be good in real flight because of the model errors.
Online learning phase
The online learning phase is designed to be implemented in real flight.
Apply the offline learned controller in real flight, then continue optimizing the control policy for real flight scenarios, in order to bridge the gap between the simplified model and the real flight dynamics.
In real flight, instead of randomly initialize the network weights, we start with the trained offline networks, thus could guarantee a stable initial control policy.
Experiments
- Offline training
- The average accumulated reward
- The average steady-state error
- Robustness test
- Random initial state
- Model generalization
- Different sizes of quadrotor radius (0.12m-0.2m-0.4m-1.2m)
- Different payload
- Disturbance and failure
- Sensor noises (add Gaussian noise with 0 mean value and 0.01 variance)
- Wind gusts (add horizontal wind from different directions)
- Actuator failures (propeller damage or motor malfunction, modeled with the Loss of Effectiveness (LOE))
- Online learning