Agile Trajectory Planning with DRL
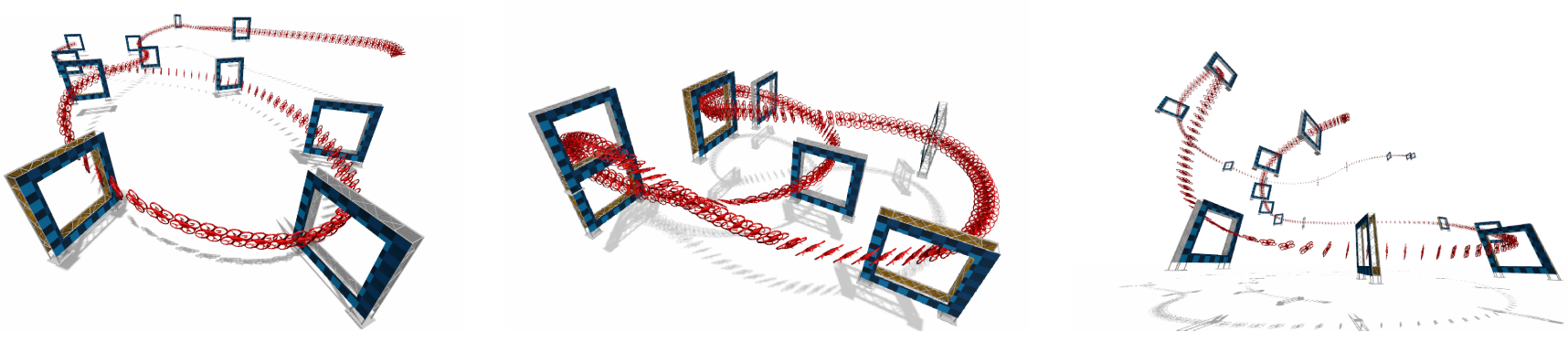
Motivation
- Fast navigation of autonomous quadrotors:
- push the vehicles to more
aggressive maneuvers. - Push quadrotors to their
physical limits. - Quadrotor competitions
- Autonomous drone racing
- IROS
- NeurIPS
- AlphaPilot challenge
- develop autonomous systems that will eventually outperform expert human pilots.
- Autonomous drone racing
- push the vehicles to more
Drone racing
- The goal is to travel through a set of waypoints as
fastas possible. - The key challenge is planning the
minimum-time trajectory.- Assuming perfect knowledge of the
waypointsto pass in advance.
- Assuming perfect knowledge of the
- The planned trajectory satisfies all constraints:
- system dynamics
- linear and angular dynamics are coupled
- compute minimum-time trajectories requires a
trade-off between maximizing linear and angular accelerations.
- diminish control authority
- system dynamics
Related works
- Sampling-based method
- RRT\(^*\)
- can be provably optimal in the limit of infinite samples.
- Rely on the construction of a graph.
- commonly combine with approaches that provide a closed-form solution for trajectories.
- drawbacks
- closed-form solution between two full quadrotor states is difficult to derive analytically when considering the nonlinear system dynamics.
- Approximate the quadrotor as a point mass.
- Polynomial representation method
- faster computation times.
- but fail to account for true actuation limits.
- lead to suboptimal or dynamically infeasible solutions.
- closed-form solution between two full quadrotor states is difficult to derive analytically when considering the nonlinear system dynamics.
- RRT\(^*\)
- Optimization-based method
- Solve the problem by using discrete-time state space representations for the trajectory.
- Rely on numerical optimization by discretizing the trajectory in time.
- Enforce the system dynamics and thrust limits as constraints.
- Require very long computation times.
- Trajectory optimization can only achieve
local optima. - Can not reliably compute feasible trajectories for
- nonlinear systems
- non-convex constraints
- when the initialization is poor
- Solve the problem by using discrete-time state space representations for the trajectory.
- RL-based method
- applications
- waypoint following
- autonomous landing
- neither managed to push the platform to its physical limits.
- applications
Contributions
- A new approach to
minimum-time trajectory generationfor quadrotors is presented.- Leveraging DRL and
relative gate observations(as the policy inputs). - Highly parallelized sampling scheme.
- maximize a 3D path progress reward.
- Adaptively compute near-time-optimal trajectories for random track layouts.
- Leveraging DRL and
- Compare to optimization-based method
- Compute extremely aggressive trajectories that are close to the time-optimal solutions provided by state-of-the-art trajectory optimization.
Computational advantageover methods based on trajectory optimization.- The learned NN policy can handle
large track uncertaintiesefficiently, which is very challenging and computationally expensive for optimization-based approaches.
- The first learning-based approach for tackling
minimum-time quadrotor trajectory planningthat isadaptive to environmental changes.- Generalization capability
- adaptive to different and unseen racing environments.
- can be deployed in
unknown, dynamic, or unstructured environemnts.
- Achieving speeds of up to \(17m/s\) with physical quadrotor.
- Video: https://youtu.be/Hebpmadjqn8.
Method
Quadrotor Dynamics
\[\begin{aligned} \dot{p} & = v, \\ \dot{v} & = q\odot c + g, \\ \dot{q} & = \frac{1}{2} \Lambda(\omega)\cdot q, \\ \dot{\omega} & = J^{-1}(\tau - \omega\times J \omega). \end{aligned}\]Full state of the quadrotor:
\[x = [p,q,v,\omega].\]Control inputs:
\[u = [f_1,f_2,f_3,f_4].\]Using 4th order Runge-Kutta method for the dynamic equation: \(f_{RK4}(x,u,\Delta t)\).
Reward Function
- Using a reward that closely approximates the true performance objective.
- Provide feedback to the agent at every time step.
- According to car racing.
Projection-based path progress reward
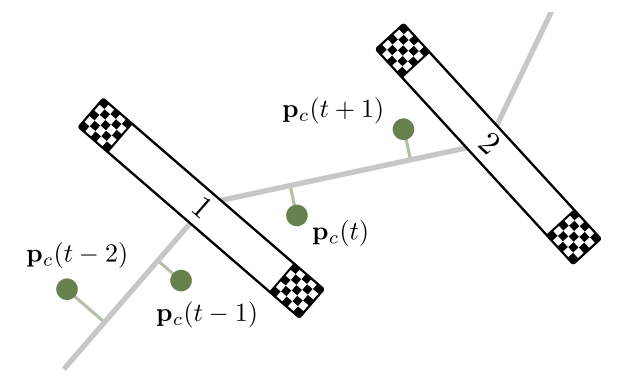
- Using straight line segments connecting adjacent gate centers as a representation of the track center-line.
- Project the position of the quadrotor onto the current line segment.
- Given the center-line position of the quadrotor \(p_c(t)\).
- Define the progress reward as follows:
where \(s(\cdot)\in\mathbb{R}\) denotes the progress along the path.
Safety reward
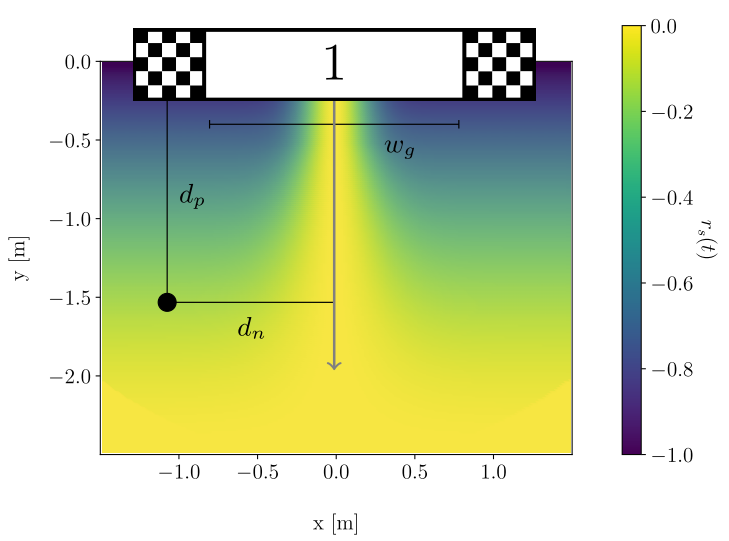
- Incentivize the quadrotor to fly through the gate center by penalizing small safety margins.
- Reduce the risk of crashing.
where
- \(f = \max[1-\frac{d_p}{d_{max}}, 0.0]\).
- \(v = \max[(1-f)\frac{w_g}{6},0.05]\).
- \(d_p\) denotes the distance of the quadrotor to the
gate plane. - \(d_n\) denotes the distance of the quadrotor to the
gate normal. - \(d_{max}\) specifies a threshold on the distance to the
gate centerin order to activate the safety reward.
Final reward function
\[r(t) = r_p(t) + a \cdot r_s(t) - b \cdot \Vert \omega_t\Vert^2 + \begin{cases} r_T & \text{if gate collision} \\ 0 & \text{else} \end{cases},\]where
- \(r_T = - \min\left[ \left( \frac{d_g}{w_g} \right)^2, 20.0 \right]\) is a
terminal rewardfor penalizing gate collisions.- \(d_g\) is the euclidean distance from the position of the crash to the gate center.
- \(\Vert \omega_t\Vert^2\) is added to counteract large oscillations.
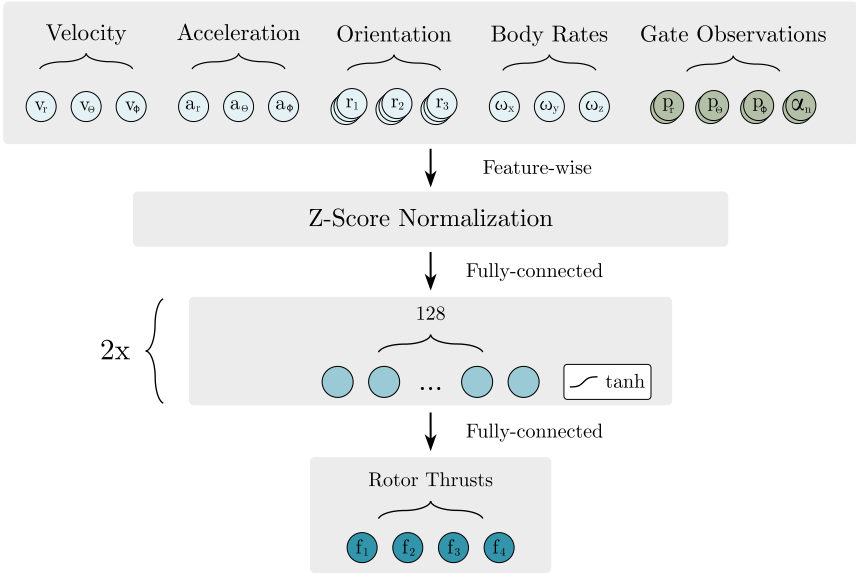
Observation Space
Consist of two main components:
- quadrotor’s state \(s_t^{quad} = [v,\dot{v},R,\omega]\in\mathbb{R}^{18}\).
- Using
rotation matrixto avoid ambiguities and discontinuities in the representation of the orientation.
- Using
- race track \(s_t^{track} = [o_1,\alpha_1,\cdots,o_i,\alpha_i,\cdots], i\in[1,\cdots,N]\).
- \(o_i = [p_r,p_\theta,p_\phi]_i\in\mathbb{R}^3\) denotes the observation for gate \(i\).
- \(\alpha_i\in\mathbb{R}\) specifies the angle between the gate normal and the vector pointing from the quadrotor to the center of gate \(i\).
Apply input normalization: z-scoring.
Action Space
\[a_t = [f_1,f_2,f_3,f_4].\]Using individual rotor commands allows for maximum versatility and aggressive flight maneuvers.
Network architecture
Policy training
- PPO algorithm
- first-order policy gradient method
- good benchmark performances and simplicity in implementation
- Challenges
- high dimensionality of search space
- complexity of the required maneuvers
- training on complex 3D race track with arbitrary track lengths and numbers of gates.
- Three key ingredients to achieve stable and fast training performance
- Parallel sampling scheme
- 100 environments in parallel.
speed-upof the data collection process.- increase the
diversityof the collected environment interactions. - initialization strategies can be designed such that
- rollout trajectories cover the whole race track instead of being limited to certain parts of the track.
- avoid overfitting to a certain track configuration.
- Distributed initialization strategy (early stages of learning)
- if each quadrotor is initialized at the
starting position- data collection is restricted to a
small part of the state space. - require a large number of update steps until the policy is capable of exploring the full track.
- data collection is restricted to a
- employ a distributed initialization strategy
ensure a uniform exploration of relevant areas of the state space.- random initialize the quadrotors in a hover state around the centers of all path segments.
- Sampling initial states from previous trajectories since the policy has learned to pass gates reliably.
- if each quadrotor is initialized at the
- Random track curriculum
- random sampling race tracks
- confront the agent with a new task in each episode.
- design a
track generator- concatenate a list of randomly generated gate primitives.
- definition: \(T = [G_1, \cdots, G_{j+1}], j\in[1,\infty)\).
- \(G_{j+1} = f(G_j,\Delta p, \Delta R)\).
- \(\Delta p\) is relative position.
- \(\Delta R\) is the orientation between two consecutive gates.
- \(G_{j+1} = f(G_j,\Delta p, \Delta R)\).
- Adjust the range of relative poses and total number of gates.
- Generate race tracks of arbitrary complexity and length.
automatically adapt the complexity of the sampled tracksbased on the agent’s performance- can be interpreted as an
automatic curriculumthat is tailored towards the capabilities of the agent. - Start the training by sampling tracks with only small deviations from a straight line.
- reduce the percentage of rollouts that results in a gate crash.
- use
crash ratiocomputed across all parallel environments to adapt the complexity of the sampled tracks. - Data collection is constrained to a certain class of tracks until a specified performance threshold is reached.
- can be interpreted as an
- Parallel sampling scheme
Experiments
Purpose
Lap timeachieved by RL-based method compare to optimization-based algorithms.Handle uncertaintiesin the track layout.- Race on a completely
unknown track. - Execute with a
physical quadrotor.
Setup
- Simulator: Flightmare
- OpenAI gym-style racing environment.
- allow for simulating hundreds of quadrotors and race tracks in parallel.
- collect up to 25000 environment interactions per second during training.
- Race tracks:
- 2019 AlphaPilot challenge
- long straight segments
- hairpin curves
- 2019 NeurIPS AirSim Game of Drones challenge
- rapid and very large elevation changes
- Split-S (for real-world experiments)
- introduce two vertically stacked gates
- 2019 AlphaPilot challenge
- Robustness test
- use random displacements of position and the yaw angle of all gates on AlphaPilot track.
- Train and evaluate the policy on random tracks, which generated by the track generator.
- Ablation studies
- Execute the generated trajectory on a physical platform.
Baseline Comparison
- Tracks: three deterministic tracks
- Baselines
polynomial minimum-snap trajectory generation- implicit smoothness property
- but the smoothness property
prohibits the exploitation of the full actuator potentialat every point in time. - lead to sub-optimal for racing.
optimization-based minimum-time trajectory generation- provide an asymptotic lower bound on the possibly achievable time for a given race track and quadrotor model.
sampling-based methods(do not compare)- due to the simplifying assumptions on the quadrotor dynamics.
- there exist no sampling-based methods that take into account the full state space of the quadrotor.
Handling Track Uncertainties
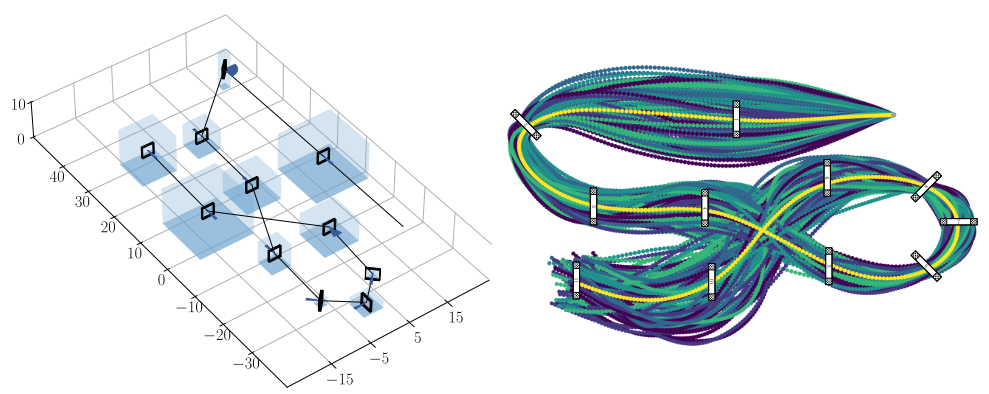
- Robustness test to
partially unknown track layouts.- specify random gate displacements on AlphaPilot track
- use bounded displacements on the position of each gate’s center and orientation in the horizontal plane: \([\Delta x, \Delta y, \Delta z, \Delta \alpha]\).
- Train a policy from scratch by sampling different gate layouts from a uniform distribution of the individual displacement bounds.
- Create 100 parallel racing environments with different track configurations for each training iteration.
- Final model is selected based on the
fastest lap timeon the nominal version of the track. - Define
two metricsto evaluate the performance of the trained policy:- the average lap time
- the crash ratio
Learning a universal racing policy
- Generate minimum-time trajectories for completely
unseen tracks. - Train three different policies on random track layouts
- differ in the training strategy
- \(\pm\) automatic track adaptation
- and the reward
- \(\pm\) safety reward
- differ in the training strategy
- Evaluate the performance of 100 unseen randomly sampled tracks.
- Choose the policy with the
lowest crash ratioon the validation set as the final model. - Adding automatic track adaptation:
- improve performance by reducing the rask complexity at the begining of the training process.
- take into account the current learning progress when sampling the random tracks.
- Adding the safety reward:
- reduce the crash ratio.
Real-world Flight
- Quadrotor
- carbonfiber frame
- brushless DC motors
- 5-inch propellers
- BetaFlight controller
- thrust-to-weight ratio of around 4
- Reference trajectory
- Generated by performing a deterministic policy rollout for 4 continuous laps on the track.
- The reference trajectory is tracked by a
MPC. - Enable the quadrotor to fly at high speeds of up to \(17m/s\).
Computation Time Comparison
- Compare the computation time of
learning-basedapproach tooptimization-basedmethod. - The computation time of the
optimization-basedmethodincreases drasticallywith thelength of the trackas the number of decision variables in the optimization problem scales accordingly. - The computation time of
learning-basedmethod instead does not depend on the length of the tracks. - Thus, this method can be applied for
large-scale environments.
Ablation Studies
- Number of observed gates (1, 2, or 3)
- Using only information about a
single future gateis insufficient to achieve fast lap times and minimize the crash ratio.
- Using only information about a
- Safety reward (\(d_{max} = \{ 0.0, 2.5, 5.0 \}\))
- The safety reward increases the average safety margin for all configurations.
- The safety reward consistently reduces the number of crashes on the test set.
References
- Y. Song, M. Steinweg, E. Kaufmann, and D. Scaramuzza, “Autonomous Drone Racing with Deep Reinforcement Learning,” 2021.